Spuštění BaseX
BaseX je open source databázový software primárně zaměřený na práci s XML soubory. BaseX je napsaný v Java 11 a lze ho tedy používat v běžných systémech a prostředích. Kromě samotného DBMS obsahuje software balík i plnohodnotné obslužné GUI, či REST webový server pro dotazování.
SW balík lze stáhnout ve čtyřech různých formách. V textu je uvažován ZIP archiv BaseX104.zip obsahující všechny dostupné komponenty. Archiv má charakter portable aplikace a stačí ho po stažení extrahovat na vhodné místo na disku, kde musí mít následně spuštěná aplikace právo k zápisu.
V adresáři bin/ je sedm spouštěcích skriptů. Pro další práci bude využit basexgui.bat (případně bash skript basexgui), který spustí grafické rozhraní pro práci s databází. Samotnou databázi, databázový server ani webový server není potřeba spouštět.
V případě existence více Java JDK v systému a možného problému s implicitním spouštěním GUI s příliš starou verzí Java lze editovat skript například následujícím způsobem k explicitnímu zavolání požadované verze Java (11+).
set JBIN="C:\Program Files\Java\jdk-11.0.11\bin"
start "" %JBIN%\javaw -cp "%CP%" %BASEX_JVM% org.basex.BaseXGUI %*
Orientace v prostředí BaseX
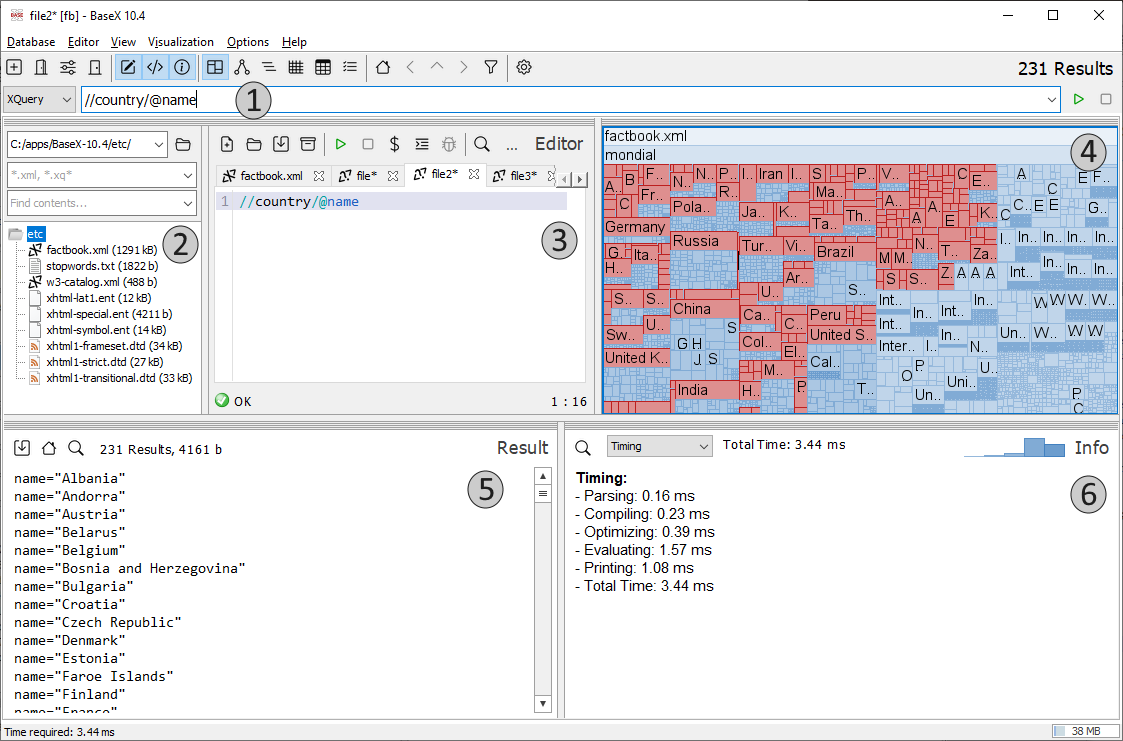
GUI aplikace je rozděleno do několika sekcí. V horní části (1) jsou tlačítka pro správu databáze, zobrazení dalších panelů a zobrazení vizualizací. Pod řádkem ikon je příkazový řádek, do kterého lze zadávat BaseX příkazy, lze v něm i spouštět XPath a XQuery dotazy, případně fulltextově vyhledávat v otevřené databázi.
Vlevo (2) je panel se stromovou strukturou souborů sloužící k navigaci v projektovém adresáři, resp. obecném adresáři na disku (nejedná se o zobrazení obsahu databáze).
Uprostřed (3) je editor, ve kterém lze editovat textové soubory otevřené skrze navigaci (2) a zároveň slouží jako worksheet pro spouštění dotazů do otevřené XML databáze. Napsaný dotaz lze spustit a případně i terminovat ikonou v řádku ikon editoru.
Vpravo (4) lze zobrazit různé vizualizace momentálně otevřené XML databáze. Na obrázku je "Map" vizuál zobrazující všechny XML soubory a jejich uzly. Velikost obdélníků přibližně odpovídá objemu dat uchovaných v příslušných uzlech. Při vyhledávání (zde dotazem na uzel typu country obsahující atribut name) jsou barevně zvýrazněné nalezené uzly.
Dole vlevo (5) je panel zobrazující výsledky XPath a XQuery dotazů spuštěných nad databází.
Dole vpravo (6) jsou zobrazeny detailní logovací informace o průběhu dotazu nebo příkazu. Mimo jiné je zde vidět, jakým způsobem byl zadaný dotaz optimalizován i samotný plán dotazu.
Založení BaseX databáze
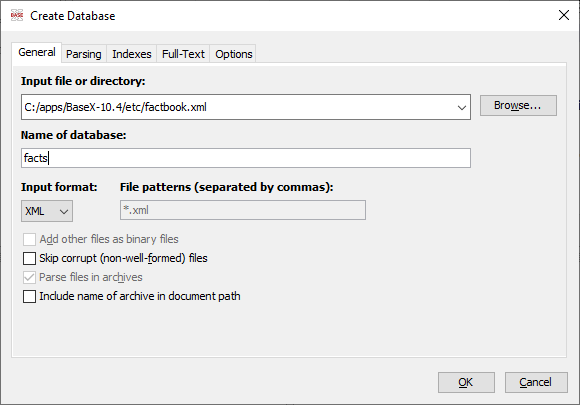
Pro další práci založíme databázi obsahující datový soubor factbook.xml, který je přiložený jako součást instalace. V GUI k tomu poslouží ikona vlevo (New...), případně navigace skrze menu Database -> New... V následném dialogu je potřeba zadat cestu k jednomu souboru obsahujícímu náplň budoucí databáze, případně cestu k adresáři obsahujícímu množinu souborů ke zpracování. Dalším podstatným údajem je název nově zakládané databáze, případně formát vstupu. V případě volby shodného názvu databáze s již existující by došlo k přepsání jejího obsahu.
Po vytvoření databáze by měl být automaticky přepnut kontext na tuto databázi a dotazy z editoru (3) a příkazy z řádku (1) se budou vykonávat vůči této databázi. Pohledem lze skutečnost ověřit v záhlaví GUI okna, které má ve svém jméně momentálně otevřený soubor v editoru a příslušný kontext.
Alternativou by bylo založení a naplnění databáze sadou příkazů vkládaných do příkazového řádku (1) s vybranou položkou Command. Příkazy nejsou case senstitive.
CREATE DB facts
OPEN facts
ADD C:\apps\BaseX-10.4\etc\factbook.xml
OPTIMIZE
XPath adresace
XPath je jazyk sloužící k adresaci podmnožiny uzlů v hierarchii XML dokumentu. Lze se s ním setkat v mnoha knihovnách a aplikacích nativně pracujících s XML daty. Výrazy jsou case-sensitive. Doporučené čtení: W3C School materiály s příklady, Aktuální verze XPath 3.1.
Nejjednodušším dotazem je nalezení elementů dle konkrétního tagu. Po náhledu do vizualizace datasetu (případně do zdrojového souboru) kliknutím například na obdélník "Germany", je patrné, že existují elementy s tagem country. Tyto elementy jsou zanořené pod uzlem s tagem mondial, což je zároveň i kořenový element.
Lomítka v zápisu znamenají přímého potomka. Dvojité lomítka mají význam libovolné úrovně zanoření mezi jmenovanými tagy. Pokud není uvedeno lomítko na začátku, implicitně se uvažuje (v této aplikaci), že první tag má být kořenový element.
(: country jako potomek mondial
v kořeni dokumentu :)
/mondial/country
(: country jako potomek mondial
kdekoliv v dokumentu :)
//mondial/country
(: country libovolně hluboko pod mondial :)
//mondial//country
(: tag country kdekoliv v dokumentu :)
//country
Pozor na různé výsledky v případě, že se hledaný tag nachází pod různými jinými tagy. Například následující dotaz má jiný počet výsledků, protože tag name se nachází v hierarchiích country/name, country/city/name a country/province/city/name.
(: 239 záznamů :)
//country/name
(: 3468 záznamů :)
//country//name
V jazyce XPath je definovaný wildcard operátor * pro případy, kdy neznáme nebo nechceme určit konkrétní název tagu či atributu. Může se hodit například v situaci, kdy je chtěno získat uzel v určitém stupni zanoření a nevyhovuje tedy adresace přes dvojité lomítko.
Úpravou předchozí sady dotazů a použitím wildcard operátoru lze rozlišit vyjmenované situace s umístěním tagu name.
(: tag name ve druhém stupni zanoření
568 záznamů :)
//country/*/name
(: tag name ve třetím stupni zanoření
2661 záznamů :)
//country/*/*/name
(: tag name v alespoň druhém stupni zanoření
3229 záznamů :)
//country/*//name
XPath predikáty
V elementu může existovat více uzlů se stejným tagem. Všimněte si například, že v datasetu je 231x tag country, ale předchozí dotaz nalezl 239 názvů těchto zemí. Následujícím způsobem lze pro každý stát vybrat pouze první (v pořadí dle XML dokumentu) název, resp. zjistit, které státy mají i alternativní název.
(: 231 záznamů :)
//country/name[1]
(: 7 záznamů :)
//country/name[2]
Hranatá závorka značí predikát, kterým lze vyfiltrovat pouze specifickou podmnožinu výsledků a vztahuje se na část dotazu vlevo od závorky. Kromě požadavku na pořadí lze klást požadavek na datovou hodnotu či obsah elementu.
V XML je možné zapisovat datové hodnoty jako vlastnost elementu, podobně jako třeba jeho třídu (class) a id v běžném HTML. Při práci s takovou hodnotu elementu v dotazování přes XPath je nutné uvést znak @ před názvem atributu. Data tímto způsobem mohou nabývat jen jedné hodnoty pro každý element, což je v kontrastu s variantou uchovávání dat jako zanořených elementů s vlastním tagem.
V ukázkovém dotazu je použita funkce text() která umožňuje získat textovou hodnotu uloženou mezi počátečním a koncovým tagem elementu. Zde je hodnota dále využita v predikátu hledajícím shodu s konkrétním textem.
(: country element dle potomka name :)
//country[name = "Czech Republic"]
(: country element dle atributu name:)
//country[@name = "Czech Republic"]
(: element name jakožto potomek country :)
//country/name[text() = "Czech Republic"]
(: 74 názvů států s populací větší 10M
(použitý atribut name nikoliv tag):)
//country[@population > 10000000]/@name
(: 7 názvů států s populací menší 1M
a negativním přírůstkem populace :)
//country[@population < 1000000 and
@population_growth < 0]/@name
Na závěr je vhodné ukázat možnost výběru rodičovského elementu pomocí výrazu ../ a možnost spojit výsledky několika XPath dotazů operátorem |. Tento operátor má charakter operátoru UNION v SQL, kdy v případě duplicitních nálezů v obou množinách bude prvek zapsán pouze jednou v množině výsledků. V ilustračním příkladu 10 států vyhovuje první podmínce a 5 států druhé.
(: 11 názvů států s populací větší 100M
nebo s městem s populací větší 5M :)
//country[@population > 100000000]/@name |
//country/city[population > 5000000]/../@name
XPath k vyzkoušení
V této sekci je několik námětů k praktickému vyzkoušení XPath dotazování nad datasetem factbook.xml. Otázky jsou řazeny subjektivně dle odhadované obtížnosti. V závorce je uveden očekáváný počet nálezů.
X1 Jaká města jsou evidovaná u České republiky? (11)
X2 Které státy mají uvedenou informaci o etnických skupinách na svém území? (183)
X3 U jakých států jsou vedeni Češi jako etnická skupina? (2)
X4 U kterých států je uvedeno, že leží na více kontinentech? (3)
X5 Jaké státy mají 10+ sousedů? (3)
Náhled do struktury BaseX databáze
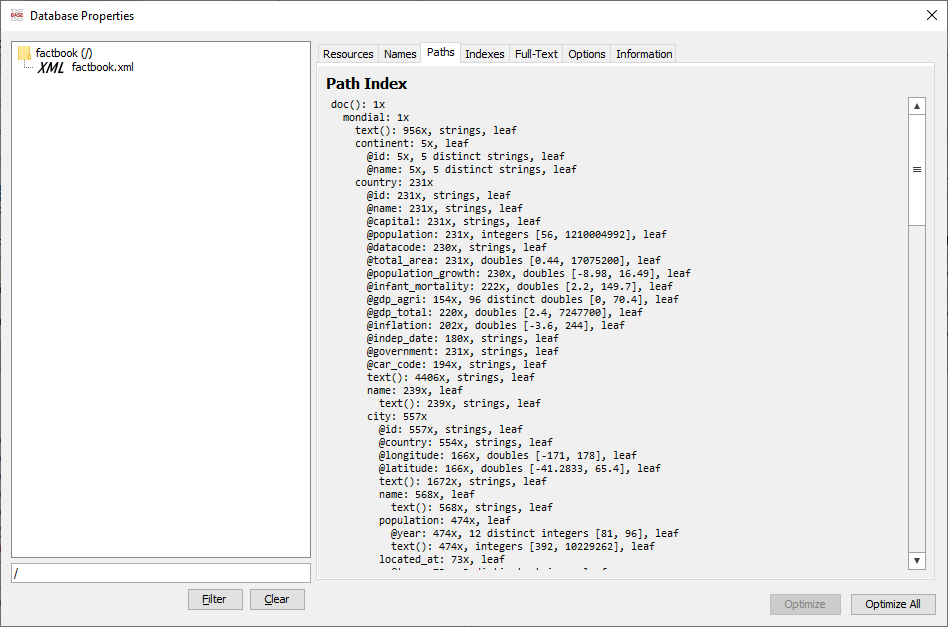
V GUI je možnost podívat se na vytvořené indexy a výsledky analytiky atributů a tagů v databázi. K tomu slouží menu Database -> Properties, nebo ikona v horní nabídce ikon. V levé části otevřeného okna je seznam importovaných souborů (v našem případě pouze jeden). V pravé části je několik karet obsahující detailní analytické informace. Na záložce Names je vidět seznam použitých názvů elementů a atributů. U každého jsou uvedené nalezené datové typy, včetně informace o rozsahu pro číselné datové typy. Na záložce Paths je vykreslen strom elementů včetně počtů instancí daného tagu. Například si lze všimnout, že kromě států, s kterými pracoval předchozí text, jsou zde i evidované organizace, hory, pouště, ostrovy, řeky, moře a jezera.
Pokud není na zmíněných záložkách nic vidět, pravděpodobně neproběhl proces optimizace. V takovém případě ho lze ručně zavolat tlačítkem vpravo dole.