V tomto cvičení je využíván dataset titanic.csv obsahující údaje o pasažérech na lodi RMS Titanic. Význam atributů:
| survived | (0 = nepřežil; 1 = přežil) |
|---|---|
| pclass | Socio-ekonomická třída pasažera (1 = vyšší; 2 = střední; 3 = nižší) |
| name | Jméno |
| sex | Pohlaví |
| age | Věk |
| sibsp | Počet sourozenců, resp. partnerů na palubě (cca. příbuzní stejné generace) |
| parch | Počet rodičů, resp. dětí na palubě (cca. příbuzní odlišné generace) |
| ticket | ID lístku |
| fare | Cena lístku |
| cabin | Číslo kajuty |
| embarked | Přístav, ve kterém se nalodil (C = Cherbourg; Q = Queenstown; S = Southampton) |
Data jsou v CSV formátu, což není nativní formát Weka, nicméně je možné ho naimportovat. Ve Weka Explorer - Open file lze zobrazit soubory typu csv a daný vstupní soubor zvolit.
Hlavním úkolem je najít, co mají společného lidé, kteří přežili, a na základě toho být schopen predikovat osud potenciálního nového pasažéra v seznamu. Target atributem je survived. Tento atribut je momentálně chápán jako datový typ numeric, což neodpovídá jeho podstatě. Abychom mohli používat metody klasifikace (nikoliv metody regrese), je nutné ho přetypovat na nominal. V našem případě lze použít binární nominal, tj. mající možnost nabývat pouze dvou stavů. Vyberme ve filtrech (obr. 1, 1) - Unsupervised - Attribute - NumericToBinary a změňme jeho argument attributeIndices na číslo sloupce survived. Filter je nutné aplikovat tlačítkem Apply. Tlačítkem Edit (obr. 1, (6)) lze zobrazit viewer, kde survived označíme jako target třídu pravým klikem na sloupec (Attribute as class). Takto zpracovaný dataset je vhodné uložit jako soubor typu arff, později poslouží jako baseline při porovnávání užitku různých způsobů předzpracování.
Poznámka - všimněte si, že v uloženém souboru je target sloupec v hlavičce definovaný jako @attribute survived_binarized {0,1}. V datech jsou dále nahrazeny prázdné hodnoty z csv symbolem otazník.
Zkusme pro současný dataset vytvořit klasifikační model. Ideální k ilustraci bude použít Functions - SMO (algoritmus pro trénování Support Vector Machine). Z logu je vidět, že velkou část rozhodovací funkce tvoří koeficienty (váhy) pro jména lidí (které jsou v datasetu jedinečné), pro ID lístků (547 z 891 záznamů jsou unikátní) a ID kajuty (101 unikátních hodnot). Díky těmto atributům je model schopen dosáhnout velké přesnosti predikce, nicméně pro predikci nad neznámými daty je toto irelevantní a pouze zbytečně komplikuje model. Odstraňme tedy tyto atributy. Na Preprocess záložce v sekci s atributy (3) označíme name, ticket, cabin a volíme remove. Změněný dataset je opět vhodné uložit pod jiným názvem k pozdějšímu srovnání.
V této fázi je také dobré podívat se na obsah sloupců nominal typu, zda-li pro stejný fakt nepoužíváme různé označení. Příkladem by mohlo být označení některých žen řetězcem "F" a jiných "Female". Nejrychleji lze toto řešit pomocí najít/nahradit v Notepad++. Také je vhodné zkontrolovat, že v datech nejsou outliers (pozorování velmi vzdálená od ostatních), případně rozhodnout, co s nimi udělat.
Některé atributy mají v datasetu chybějící hodnoty. Otázka, jak vyřešit tento problém, je často v textech o data-miningu zmiňována, ale neexistuje obecně ideální řešení. Nejčastější možnosti jsou:
V našem případě je problém s atributy embarked (2, 0% chybějící) a age (177, 20% chybějící). Pro první případ se můžeme pokusit podívat, zda-li na první pohled nejde odvodit místo nástupu z jiného atributu. Nejnadějnější z příbuzných atributů se jeví fare (cena lístku by mohla být mimo jiné závislá na místě nástupu), ticket (dá se očekávat, že skupina lidí jedoucí na jeden lístek nastoupila ve stejném místě), případně cabin. Ani pro jeden atribut ale není v datasetu řádek se shodnou hodnotou. Vzhledem k tomu, že jde pouze o 2 záznamy, což je zanedbatelné množství, jeví se jako nejekonomičtější řádky zahodit. Ve Weka se zahození provede pomocí Filter - Unsupervised - Instance - RemoveWithValues (attributeIndex = číslo atributu; matchMissingValues = true; nominalIndices = "").
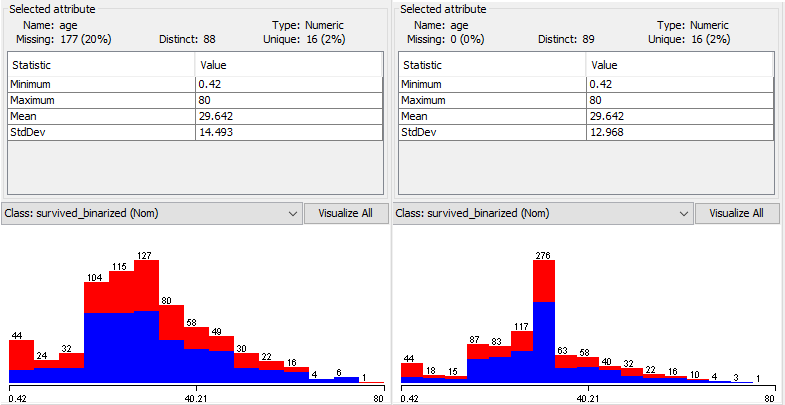
Problém s věkem již nebude možné ignorovat. 20% je velká část datasetu a zároveň se tento atribut zdá důležitým při tvorbě modelu. Zkusme dosadit za chybějící data střední hodnotu atributu. Filter - Unsupervised - Attribute - ReplaceMissingValues nahradí všechny chybějící hodnoty ve všech atributech. Je tedy vhodné tento filter volat až v době, kdy jsou aplikované ostatní řešení chybějících hodnot. Na obrázku 2 je zachycena charakteristika dat v daném sloupci. Všimněte si, že byla změněna směrodatná odchylka a celkový tvar histogramu. Toto řešení může vést ke snížení kvality odhadu pro osoby s věkem kolem 29,6 (kromě "pravých" záznamů teď do kategorie spadají i záznamy, u kterých netušíme, kolik let jim ve skutečnosti bylo). Takto upravený dataset uložme pod novým jménem.
Alternativním přístupem k řešení chybějícího věku by bylo vytvořit prediktivní model nad tímto datasetem pro target atribut age. Dá se spekulovat, že na základě informace o počtu příbuzných stejné/odlišné generace, o společenské třídě, či ceny lístku by šlo udělat přesnější odhad věku pasažéra. Otázka: stojí to za to (práce navíc, která nemusí zlepšit model, ba naopak ho může zhoršit kvůli zanesení bias)?
Některé algoritmy jsou definované pouze pro diskrétní argumenty (např. hledání apriori asociačních pravidel). Můžeme se tedy rozhodnout v rámci preprocessingu pro diskretizaci numerických hodnot. Slouží k tomu filter Unsupervised - Attribute - Discretize. Filtr nadefinuje rozsahy hodnot (bin/koš) sloužící jako nominální hodnoty daného atributu. V nastavení filtru je potřeba zvolit attributeIndices (seznam čísel atributů, na které filtr aplikovat), bins (počet kategorií), findNumBins (zda-li algoritmus má sám odhadnout počet binů).
Aplikujeme filtr na dataset před doplněním středních hodnot za chybějící hodnoty ve sloupci age. V nastavení volíme atributy age, sibsp, parch a fare; a automatický počet binů. Všimněte si, že v každém případě byl zvolen odlišný počet binů. V atributu age nyní nahradíme chybějící hodnoty novou textovou hodnotou "N/A". K tomu slouží filtr Unsupervised - Attribute - ReplaceMissingWithUserConstant, kde v nastavení zvolíme nominalStringReplacementValue = N/A a attributes = ID_atributu_age. Soubor s datasetem opět uložte pod jiným názvem.
Poznámka - v případě, že v datech máme numerické hodnoty nesoucí význam číselníku, resp. kategorií (atribut pclass), je vhodnější použít filtr Unsupervised - Attribute - NumericToNominal.
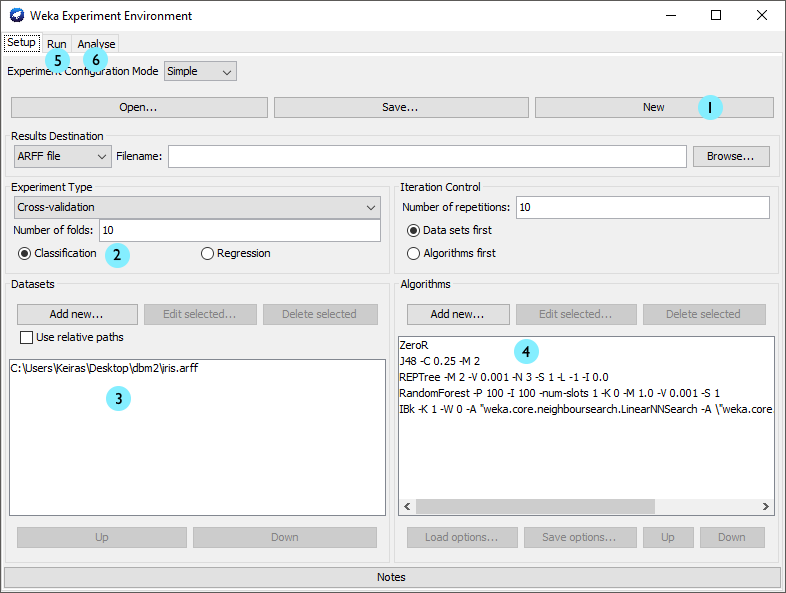
Postupně jsme vytvořili 4 datové arff soubory v různých částech preprocessingu. Zkusme vytvořit experiment, ve kterém zjistíme, zda-li naše úpravy vedly ke kvalitnějšímu modelu. Ve Weka Experimenter vytvoříme nový experiment (obr. 3, (1)), zvolíme klasifikaci (2) a vybereme datasety (3). Jako klasifikační algoritmy doporučuji zvolit: ZeroR (baseline), NaiveBayes, SMO, IBk (kkn 5), J48. Spustíme test (5) a na záložce Analyse (6) načteme výsledky.
Při porovnání modelů zvolených algoritmů se nejlépe jeví rozhodovací strom J48, který je signifikantně lepší než naivní Bayes na 3 ze 4 datasetů, lepší než SMO na 2, lepší než IBk na 1. V případě nepředzpracovaného datasetu je signifikantně horší než SMO, nicméně to může být způsobeno přílišným overfitem SMO pomocí id atributů.
Tlačítkem Swap v sekci nastavení testu můžu změnit, zda-li porovnávám algoritmy na datasetech, nebo datasety na algoritmech. Zvolím-li jako baseline dataset s odstraněnými sloupci name, ticket a cabin, vidím, že signifikantní rozdíly jsou pouze vůči nepředzpracovanému datasetu. Diskretizace a řešení chybějících hodnot tedy nevedlo k signifikantní změně v kvalitě modelu.