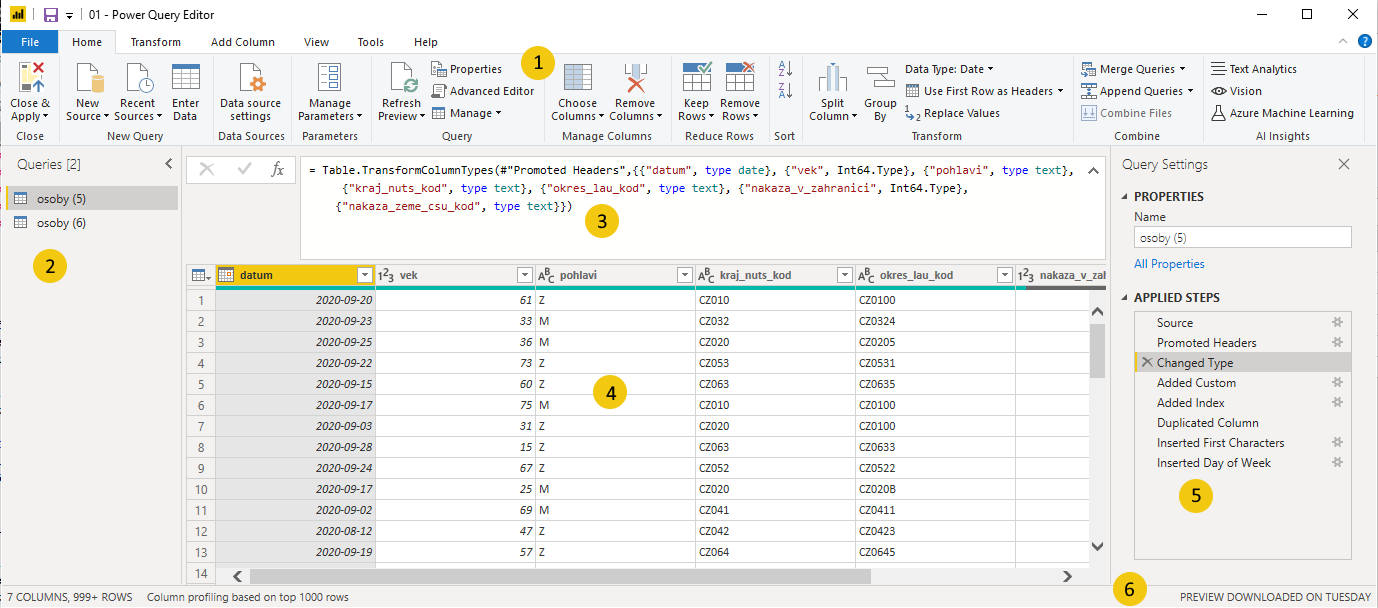
Aplikace Power BI používá integrovaný engine k zpracování dat s názvem Power Query. S tímto enginem se můžete mimo jiné setkat i v kancelářském software MS Excel. Z prostředí Power BI Desktop se do rozhraní Power Query nejjednodušeji lze dostat přes ikonu Home -> Transform Data. Uživatelské rozhraní sestává z jednoho okna (obr. 1), kde v centrální části je náhled na aktuálně zpracovaná data, nahoře je karta ikon pro běžné transformace a vpravo je lineární řetězec definovaných transformací. Entita v tomto prostředí se nazývá query a seznam těchto entit v rámci otevřeného reportu je v levém sloupci.
V sekcí Home -> Manage Columns jsou dvě ikony pro základní transformaci měnící dimenzionalitu dat - odstranění atributů (sloupců). Rozdíl mezi nimi je pouze v tom, jakým způsobem se sloupce zvolí. Ikona Choose Columns nabídne seznam atributů a zaškrtávacím políčkem uživatel indikuje ty, které mají zůstat. Oproti tomu Remove Columns odstraní momentálně vybrané sloupce, resp. v podnabídce je možnost výběr logicky negovat.
Pro potřebu redukce řádků (záznamů) existuje dvojice ikon v sekci Home -> Manage Rows, první z nich je pozitivní, tj. nechá záznamy vyhovující zvolené podmínce, druhá je negativní, tedy smaže záznamy vyhovující podmínce. Podmínky zde nemohou být příliš komplexní. Lze odstranit horních, resp. dolních N řádek, řádky obsahující chybu, řádky prázdné nebo řádky v nějakém ohledu duplicitní. Duplicitou se rozumí kombinace hodnot ve vybraných sloupcích. Např. v příkladu z předcházejícího cvičení by při selekci atributů Pohlaví a NUTS3 (kraj) a volbě odstranit duplicity zbylo jen 30 záznamů - první muž a první žena pro každý kraj při průchodu seřazenými daty shora.
I když ve své podstatě není nezbytné redukovat dimenzionalitu dat již v tomto kroku, je to vhodné kvůli úspoře výpočetního času a paměti. Z Typicky tato redukce bývá jednou z prvních operací v řetězci transformací.
Kromě horní karty s ikonami je v uživatelském rozhraní i několik jiných aktivních prvků. V záhlaví datové tabulky jsou u jména atributu dvě tlačítka. Levé z nich slouží jako přepínač datových typů. Vhodné nastavení datových typů je důležité pro správnou funkionalitu vizulizací a agregací. Pokud by atribut s čiselným charakterem byl definován jako text, nepůjde jeho hodnoty numericky agregovat a změní se i způsob jeho řazení.
Filtrovací ikona vpravo od názvu atributu skrývá podobnou nabídku jako v prostředí MS Excel. Nachází se zde možnost data seřadit podle hodnoty v příslušném sloupci a vyfiltrovat záznamy dle hodnoty v daném sloupci. Filtrace lze provést určením příslušného pravidla (číslo v rozmezí od-do, text začínající určitým řetězcem, datum vzálené maximálně X dnů od dneška, ...) nebo zaškrtnutím konkrétních hodnot. Je potřeba si dát pozor, protože ve výpisu hodnot nemusí být všechny, které se nachází v datasetu. Není-li nastaveno jinak, nástroj se orientuju pouze podle prvních 1000 záznamů. Takto vyfiltrovaná data budou opět odstraněna z datasetu, stejně jako v předchozím postupu.
Nástroj nabízí dvě tzv. agregační operace, které nějakým způsobem slučují podobné záznamy a vyčíslují jejich kombinovanou hodnotu atributu. Prvním z nich je operace Group By, která by měla být známa z jazyka SQL. Příslušná ikona je Transform -> Group By. Po stisknutí se objeví dialog, ve kterém je potřeba zvolit atribut, podle kterého se budou data slučovat, a operaci aplikovanou na vybraný sloupec. Pokud uživatel zvolý advanced, nikoliv basic mód, má možnost pracovat s více atributy. Na obr. 2 je ilustrační příklad slučování dle pohlaví a kraje.

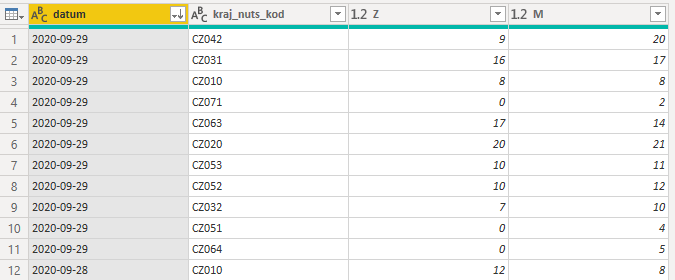
Druhým agregačním mechanismem je tzv. pivotování sloupců. Při označení sloupce a zvolení Transform -> Pivot Column je v dialogu nutné nastavit, jaký sloupec má charakter sumarizované veličiny a zvolit příslušnou funkci. Po potvrzení dojde k operaci, při které se místo původního sloupce vytvoří N nových sloupců, jeden pro každou unikátní hodnotu vyskytující se v původním sloupci. Řádky budou redukovány tak, aby zbyly pouze unikátní kombinace hodnot zbylých atributů. V nově vytvořeném sloupci pak budou hodnoty odpovídající sumarizované veličině pro příslušnou kombinaci atributů.
Př. uvažujme dataset s atributy datum, věk, pohlaví, kraj. Po označení atributu pohlaví k pivotování volíme atributu věk s funkcí count k agregování. Výsledná tabulka obsahuje původní sloupce datum a kraj. Kromě toho vznikly dva sloupce - pohlaví_Z a pohlaví_M ve kterých jsou hodnoty počtu nových případů v daném kraji a dni. (obr. 3)
K operaci pivot existuje i obrácená (nikoliv reverzní ve smyslu získání původních hodnot) operace Transform -> Unpivot Columns. Je potřeba označit množiny sloupců, které odpovídají kategoriím budoucího atributu. Po provedení se roznásobí počet řádek počtem odpivotovaných sloupců a vzniknou dva atributy. Jedním z nich je atribut obsahující kategorie z hlaviček sloupců, druhý z nich je sloupec s hodnotami.
Každá použitá operace je uváděna v pravé části uživatelského rozhraní (obr. 1, zn. 5). Kliknutím na různé kroky v seznamu lze zobrazit náhled datové tabulky v příslušné fázi. Pokud by chtěl uživatel některý z kroků smazat nebo změnit jeho parametry, lze k tomu použít ikonu křížku vlevo od názvu kroku, resp. ikonu ozubeného kola vpravo od názvu kroku. Je potřeba si ale dát pozor na kroky následující, které pravděpodobně předpokládají určitou strukturu nebo vlasnost dat. Nové transformace lze také vkládat mezi jednotlivé kroky a není nutné je umisťovat na konec posloupnosti transformací.
Užitečná může být možnost naklonovat query, nebo vytvořit query, která se bude na jinou odkazovat. To lze provést přes nabídku po kliknutí pravým tlačítkem myši na název query v seznamu vlevo. Volba Duplicate vytovoří kopii bez provázání, Reference se bude odkazovat na výsledný dataset po všech úpravách. Pokud by později došlo k změně transformačního řetězce v referované query, projeví se změny i ve všech navázaných.
data: COVID-19: Přehled osob s prokázanou nákazou dle hlášení krajských hygienických stanic (v2) [CSV] + převodník NUTS kódů území [pdf].