
V aplikaci Power BI je možné využít několik technik k vysvětlení pozorované situace v modelu, k predikci budoucího vývoje, či k sestavení What-If analýzy. Osobně se ale nedomnívám, že je toto silnou stránkou produktu, ale spíše jde o jakousi funkčnost nad rámec hlavního scope. Například výstupy u interpolací a extrapolací dle grafu nejsou řádně vysvětleny a ani není možně získat předpis aproximační linie. Pokročilé nebo matematicky tíhnoucí uživatele tedy následující pravděpodobně nenadchne a budou si muset předzpracovaná data vyexportovat do jiného nástroje.
Kromě přístupů popisovaných níže je možné využívat několik AI Insights a Azure Machine Learning analytik, které jsou ale dostupné pouze přihlášeným uživatelům v rámci některé z placených licencí. Reálně jsem s nimi nikdy nepracoval a nemohu se tedy vyjadřovat k jejich možnostem a kvalitě.
U většiny vizualizací je možné přepnout se na záložku Analytics (vedle záložek Fields a Format, ve sloupci Visualizations). Konkrétní množina nabízených prvků k vykreslení závisí na použité vizualizaci. Typicky je možné zobrazit linii představující maximální, minimální, průměrnou, či mediánní hodnotu, případně nějaký percentil. U vizualizací typu spojnicového grafu lze navíc vykreslit trend a předpověď (extrapolaci).
Nastavení trendové linie je poměrně strohé, kromě jejího vzhledu lze nastavit pouze zda bude vytvořena pro každou z datových řad, nebo pouze za celkový souhrn. Linie bude vždy přímkou, polynomické křivky nejsou podporované (narozdíl např. od MS Excel). Linie bude vytvořena na základě aktuálně filtrovaného datasetu (viz obr.1), nelze tedy např. ve vizualizaci pracovat s úsekem několika měsící a vykreslit trend pouze pro poslední měsíc.
Pokud se ve vizualizi nachází pouze jedna datová řada, je k dispozici křivka (obr. 2) popisující předpověď pro následujících několik období, kdy počet období lze volit. Kromě toho tento nástroj chápe koncept sezonality - tedy periody v datech, resp. cyklického změny hodnot. Šířka periody je automaticky detekovaná, ale uživatel ji může i pevně zvolit. Kromě toho lze zadat, aby posledních několik datových bodů bylo ignorováno, což vytvoří predikční křivku pro data, u kterých známe jejich skutečnou hodnotu. Toho by šlo využít pro stanovení kvality odhadu (viz koncept oddělní trénovací a testovací množiny v následujících cvičení). Pokud by data z predikce měla být dále použita, je možné je extrahovat do souboru přes ikonu tří teček v pravém horním rohu vizualizace.

Poslední možností nabízenou přímo ve vizualizacích je kontextová volba Analyze nad datovým bodem ve vizualizaci. Power BI se snaží vyhodnotit, co vedlo ke změně hodnoty v tomto bodě oproti předcházejícímu datovému bodu. Z osobní zkušenosti je občas vysvětlení zajímavé, občas je naprosto mimo. Na obrázku 3 demostruji spíše povedenou analýzu, která by mohla uživatele vést k vyvození podezření na lokální ohnisko, což je také to, co se ve skutečnosti v té době stalo.

Vizualizace dekompozičním stromem umožňuje strukturovaně znázornit z čeho se skládá zvolená metrika pomocí průchodu přes různé dimenze. Připadá mi to jako vhodný nástroj pro explorační pohled na data. V každém kroku je možné zvolit konkrétní dimenzi, přes kterou mý být provedena drill down operace, nebo nechat aplikaci, aby sama zvolila takovou dimenzi, kde se nachází největší, resp. nejmenší hodnota. V nastevení je vysvětlovaná metrika umístěna do sekce Analyze, uvažované dimenze jsou umístěné do sekce Explain by.
Vizualizace se relativně rychle přepočítává a je tedy možné interaktivně zkoumat různé průchody a sledovat například rozdělení některé z dimenzí.
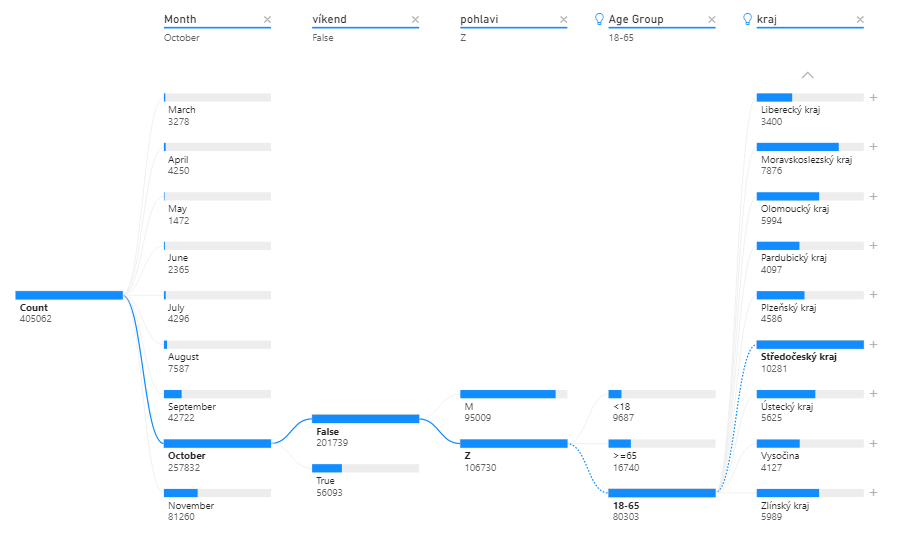
Vizualizace Key Influencers se pokouší o vysvětlení zvolené metriky pomocí množiny vysvětlujících atributů. V samotné vizualizaci zobrazí hodnoty atributů, které významným způsobem přispívají k nárůstu nebo poklesu metriky. Po kliknutí na některou z hodnot se zobrazí proporční graf nárůstu vůči ostatním hodnotám atributu.
Na obrázku 5 vizualizace vyhodnotila tři klíčové faktory ovlivňující průměrný počet nových pozitivních případů per měsíc, kraj, věková skupina a víkend. Číslo samo o sobě je špatně interpretovatelné kvůli příliš detailnímu členění. Dává tak větší smysl sledovat spíše než absolutní hodnotu, její poměr.

K demonstraci možného použití what-if přístupu zpracuji otázku - jaké je momentálně reprodukční číslo R v probíhající Covid epidemii v ČR a jaké jsou na jeho základě vyhlídky do následujících dnů.
Prací navazuji na předchozí cvičení a používám datový soubor do 9.11. včetně. Pro své účely budu r-factor modelovat na základě laické domněnky, že průměrná doba mezi pozitivním testem nakaženého a pozitivním testem jím nakažených kontaktů je 14 dnů. R-factor chápu jako počet kontaktů, který průměrně každý pozitivně testovaný nakazil. Předpokládám, že nakažení jsou buď pozitivně testovaní, nebo v izolaci (což v současné situaci neplatí, protože trasování nestíhá a vynechává některé případy).
Prvním krokem bude zavedení do datového modelu nového parametru pojmenovaného r-factor. V hlavním okně Power BI k tomu slouží Modeling -> New parameter. V dialogovém okně je kromě názvu potřeba zvolit datový typ a rozsah hodnot. V mém případě volím desetinné číslo v rozsahu 0-2 a inkrementem 0,1. Napárování tohoto parametru na nově vytvořený slicer je do budoucna výhodné. Po potvrzení se vygeneruje nová datová tabulka obsahující čiselnou řadu.
V druhém kroku budu chtít přepočítat hodnoty pozitivně testovaných na týdenní klouzavý průměr, abychom měli k dispozici hladší křivku. K tomu budu potřebovat výpočíst tzv. Measure, nikoliv vytvářet nový atribut. Measure je definovaná pomocí syntaxe Data Analysis Expressions (DAX), jejíž znalost je nad rámec tohoto cvičení. Pomůžeme si tedy předpřipravenou šablonou a vhodně ji upravíme. Šablony DAX výrazů jsou v Home -> Quick Measure. Před otevřením dialogu je vhodné mít označenou příslušnou faktovou tabulku, do které measurement bude přidán. V dialogu volíme Rolling Average kalkulaci a nastavíme, že: počítáme sumu denního přírustku pacientů; jako datum volíme hierarchii z tabulky kalendář; periodou je den; uvažujeme 6 dnů před a 0 po.
Nyní vykreslíme do spojnicového grafu na osu X hierarchii datumu z tabulky kalendář a na osu Y hodnoty původních přírůstku a hodnoty klouzavého průměru. Ke správnému zobrazení je potřeba hierarchii expandovat na nejnižší level pomocí ikony dvojzubce v pravé horní části grafu. Opticky by měl klouzavý průměr vyhlazovat původní křivku a být mírně posunutý doprava, jelikož v čase x je zobrazen průměr hodnot (y(x-6), ..., y(x)).
Nechtěným artefaktem je, že některé datumy původně prázdné nyní mají vypočten klouzavý průměr, který je zároveň podhodnocen. K odstranění artefaktu je možné upravit vygenerovaný kód pro measure. Konkrétně použijeme podmínku, která za určité situace vrátí prázdnou hodnotu. Nejpřímočařejší podmínkou je dotaz na prázdnost atributu s počtem případů pro daný den (je rozdíl mezi prázdností BLANK a hodnoutou nula). K tomu nám může posloužit IF(ISBLANK(MAX('osoby (6)'[cases])), BLANK() , {původní výraz}. Pokud tedy nebude k dispozici žádný datapoint z přílušného data, funkce vrátí prázdnou hodnotu a tím dosáhneme oříznutí plovocího průměru na posledním dnu v datasetu.
Rolling average 7D =
IF(
ISFILTERED('kalendář'[Date]),
ERROR("Time intelligence quick measures can only be grouped or filtered by the Power BI-provided date hierarchy or primary date column."),
VAR __LAST_DATE = LASTDATE('kalendář'[Date].[Date])
RETURN
IF(
ISBLANK(MAX('osoby (6)'[cases])),
BLANK(),
AVERAGEX(
DATESBETWEEN(
'kalendář'[Date].[Date],
DATEADD(__LAST_DATE, -6, DAY),
__LAST_DATE
),
CALCULATE(SUM('osoby (6)'[cases]))
)
)
)
Posledním krokem je vytvořit křivku odpovídající predikci vývoje. Křivka bude nabývat hodnoty referenčního klouzavého průměru před 14 dny a tato hodnota bude vynásobena R faktorem. Referenční honotu můžeme získat obdobným přístupem jako u minulé křivky, pouze upravíme datový rozsah, z kterého je tvořen klouzavý průměr, tedy -20 až -14 namísto původního -6 až 0. Vynásobení R faktorem je poměrně přímočaré pomocí běžného operátoru *.
Abychom opět smysluplně vymezili definiční obor vykreslované funkce, budeme muset vytvořit vícenásobnou podmínku, kterou zavedeme levou a pravou oblast ležící mimo definiční obor. Levou oblastí jsou všechny datumy, pro které existuje záznam o počtu případů. Pravou oblastí se rozumí více jak 14 dnů od nejvyššího datumu v datasetu, jelikož by zde již nedával smysl klouzavý průměr na rozasahu -20 až -14 dnů.
Forecast =
IF(
ISFILTERED('kalendář'[Date]),
ERROR("Time intelligence quick measures can only be grouped or filtered by the Power BI-provided date hierarchy or primary date column."),
VAR __LAST_DATE = LASTDATE('kalendář'[Date].[Date])
RETURN
IF(
OR(
ISBLANK(CALCULATE(MAX('osoby (6)'[cases]), 'kalendář'[Date] IN { __LAST_DATE - 14 })),
NOT(ISBLANK(MAX('osoby (6)'[cases])))
),
BLANK(),
AVERAGEX(
DATESBETWEEN(
'kalendář'[Date].[Date],
DATEADD(__LAST_DATE, -20, DAY),
DATEADD(__LAST_DATE, -14, DAY)
),
CALCULATE(SUM('osoby (6)'[cases]))
) * 'r-factor'[r-factor Value]
)
)
Po přidání křivky s předpovědí vývoje do vizualizace lze pomocí ovládacího prvku pro hodnotu R faktoru názorně vidět, jak se bude kalkulace měnit. Díky/kvůli tomu, z jakých předpokladů jsem vycházeli a jak jsme samotnou kalkulaci implementovali, lze odhadnout aktuální reprodukční číslo opticky - křivka predice by měla relativně hezky navazovat na křivku klouzavého průměru. V mém případě bych odhadoval R = 0,85 pro 10.11.
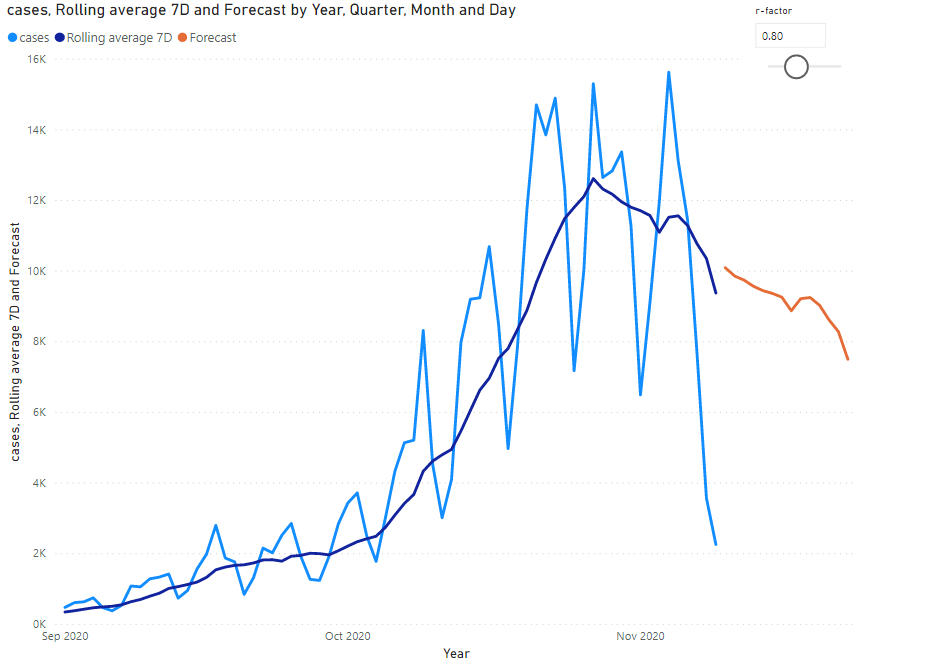
Výše uvedené je velmi zjednodešená kalkulace za účelem předvedení funkcionality produktu Power BI. Zmíněné předpoklady věřím, že nejsou v současnosti naplněny.