Materiál k cvičení INS týden #10-11, sezona 2023/2024
Předpřipravené míry a DAX
S jazykem DAX již bylo pracováno v předcházejících cvičení pro založení tabulky Kalendáře a pro odvození sloupce s hodnotou dne v týdnu. V tomto cvičení se budeme věnovat vytváření vlastních měr a jejich použití v reportu.
Míra je výpočet, který se provádí nad daty a vrací jednu hodnotu. V PowerBI se míry definují v Report → Modeling → New Measure/Quick Measure. Výsledný výpočet je možné použít v reportu jako atribut.
Výpočet denních nákaz a průměry přes kategorie
PowerBI nabízí několik typů měr, které lze zadat skrze dialogové okno a není potřeba znát detailně DAX. Prvně budeme chtít přidat možnost vyjádřit průměrné denní počty nákaz, což by se mohlo hodit například pro pozorování, jestli o svátcích (viz Modelování: Státní svátky) bylo skutečně zachyceno méně případů.
V datech je momentálně informace uchována po jednotlivých případech a nelze tedy bez další agregace získat požadovanou hodnotu ve vizuálu. Řešením může být zavedení míry jako:
- Vybrat
Quick Measure → Average per category - V dialogu vybrat
Count of idz tabulkyosobyjako hodnotu aDatez tabulkyKalendářjako kategorii. - Potvrdit vytvoření míry.
V modelu se objeví nová míra pravděpodobně pojmenovaná jako Count of id average per Date (lze přejmenovat), která má následující definici:
![]()
Count of id average per Date = AVERAGEX( KEEPFILTERS(VALUES('Kalendář'[Date])), CALCULATE(COUNTA('osoby'[id])) )
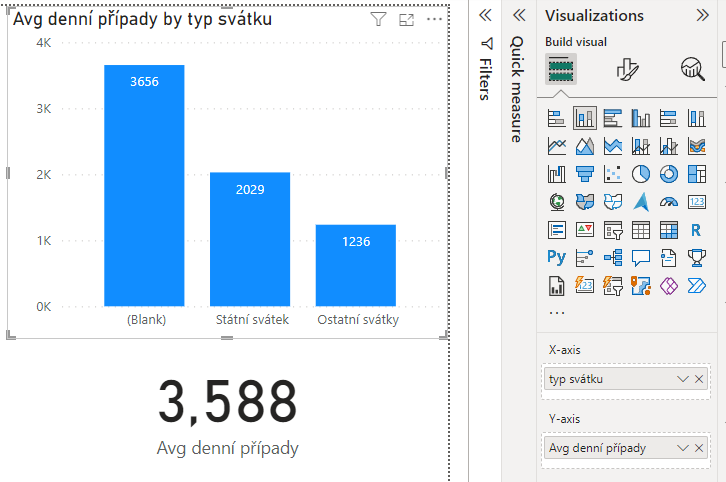
Fig — Využití míry pro vizualizaci průměrných počtů případů ve svátcích a běžných dnech.
Q1: Zkuste vytvořenou míru použít i pro jinou sestavu vizuálu. Například pro zobrazení průměrného počtu případů v jednotlivých měsících. Je výsledek správně? (březen 2020 má některé dny bez nákaz)
Kumulativní počty přes období
Další z nabízených měr je Quick Measure → Running total. Tato míra vrací kumulativní součet hodnoty přes zvolené období. V našem případě bychom chtěli zobrazit kumulativní počet případů přes jednotlivé dny. V dialogu je tedy potřeba vybrat Count of id z tabulky osoby jako hodnotu a Date z tabulky Kalendář jako kategorii.
Míra Count of id running total by mohla mít následující definici:
![]()
Count of id running total in Date = CALCULATE( COUNTA('osoby'[id]), FILTER( ALLSELECTED('Kalendář'[Date]), ISONORAFTER('Kalendář'[Date], MAX('Kalendář'[Date]), DESC) ) )
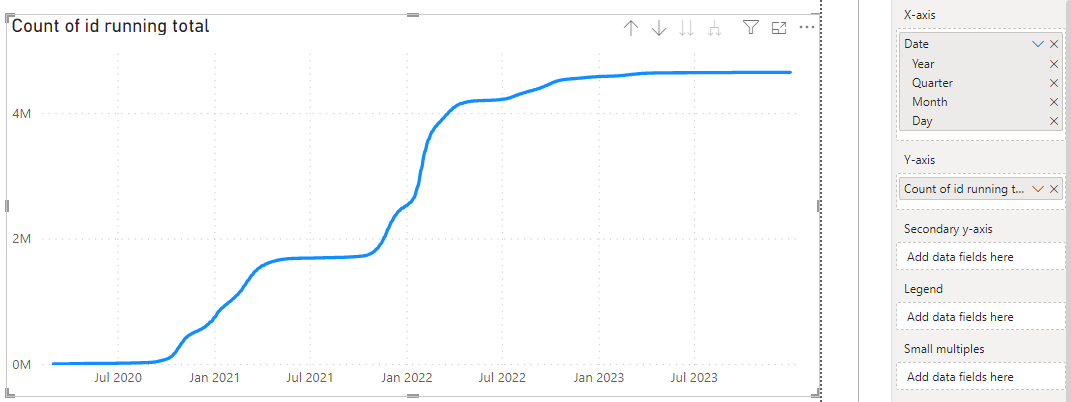
Fig — Využití míry pro vizualizaci kumulativního počtu případů přes jednotlivé dny.
Q2: Vyzkoušejte podobnou míru
Year-to-date total. Jaký je v nich rozdíl?
Klouzavé průměry
V datech, kde je časová složka s krátkým periodickým cyklem, lze využít techniku klouzavého průměru pro zamazání těchto cyklů a získání obecnějšího trendu. V našem případě můžeme chtít zobrazit klouzavý průměr počtu případů přes 7 dní.
- Vybrat
Quick Measure → Rolling average - V dialogu vybrat
Count of idz tabulkyosoby, atributDatez tabulkyKalendářa dále zvolit, že se jedná o periodu 7 dnů. - Potvrdit vytvoření míry.
Vytvoří se míra Count of id rolling average s definicí:
![]()
Count of id rolling average = IF( ISFILTERED('Kalendář'[Date]), ERROR("Time intelligence quick measures can only be grouped or filtered by the Power BI-provided date hierarchy or primary date column."), VAR __LAST_DATE = LASTDATE('Kalendář'[Date].[Date]) RETURN AVERAGEX( DATESBETWEEN( 'Kalendář'[Date].[Date], DATEADD(__LAST_DATE, -3, DAY), DATEADD(__LAST_DATE, 3, DAY) ), CALCULATE(COUNTA('osoby'[id])) ) )
Míru lze nyní použít například k vykreslení průběhu počtu případů přes jednotlivé dny.
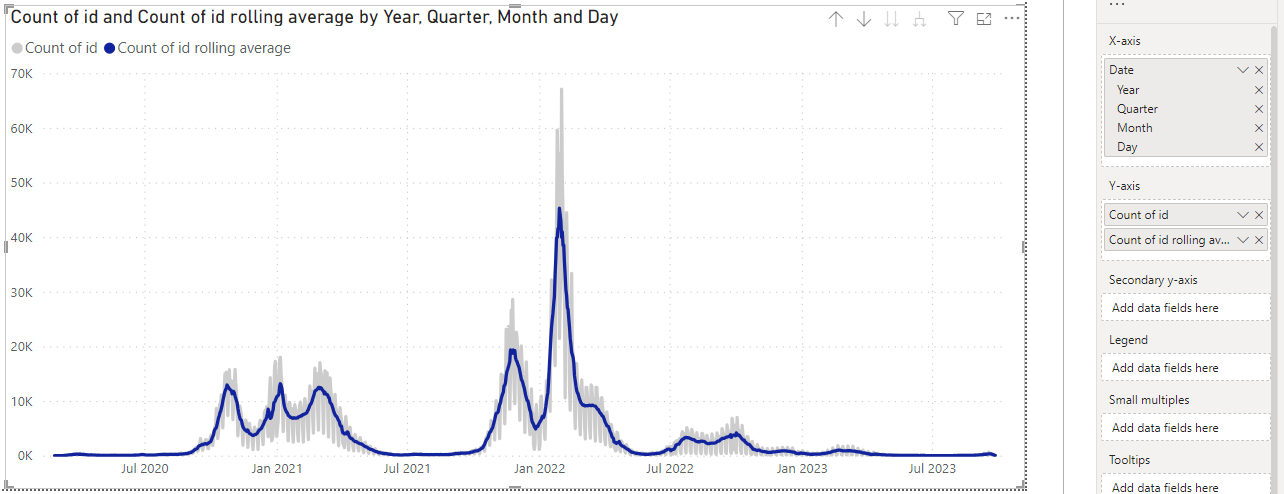
Fig — Vykreslení původních denních hodnot a s velkou cyklickou variabilitou a klouzavého průměru přes 7 dní.
Vlastní míry
Pokud by z nějakého důvodu nestačilo použití předpřipravených měr, je možné vytvořit vlastní. To lze provést přes Report → Modeling → New Measure a do příkazového řádku vložit příslušný příkaz.
Denní nákazy (revisited)
Pokud bychom chtěli vytvořit míru pro denní nákazy, můžeme využít funkce CALCULATE, která provádí výpočet v kontextu zadaných filtrů. Jako výpočetní operaci lze použít COUNTA, která vrací počet neprázdných hodnot ve zvoleném sloupci, případně COUNTROWS, která vrací počet řádků v tabulce. Výsledný vzorec bude mít jednu z těchto forem:
![]()
x1 = CALCULATE(COUNTROWS('osoby'))
![]()
x1 = CALCULATE(COUNTA('osoby'[id]))
Pro ilustraci vykreslete výsledek na nový list reportu, kde bude vizuál typu Matrix s řádky Kalendář[Date] a jako hodnotu použijte Count of id average per Date a nově vytvořenou x1. Výsledek bude shodný pro jednotlivé dny, ale odlišný pro souhrny za měsíce.
Q3: Proč je výsledek pro souhrny za měsíce odlišný? Jak se
x1liší od vygenerovaného vzorce?
Poměrová změna za 7 dnů
Jedna z často používaných metrik během pandemie bylo reprodukční číslo R0, které lze hodně laicky odhadnout jako poměr počtu nakažených v daný den a počtu nakažených před 7 dny. Takový výpočet je možné v PowerBI provést pomocí míry:
![]()
x2 = VAR PreviousDailyCases = CALCULATE([x1], DATEADD('Kalendář'[Date], -7, DAY)) RETURN IF(ISBLANK(PreviousDailyCases), BLANK(), ([x1] / PreviousDailyCases) )
Ve vzorci je několik nových konceptů. Prvním z nich je proměnná, která se zavádí pomocí VAR a následně se používá v dalších výpočtech. Jelikož se nyní jedná již o výpočetní blok, je potřeba výsledek vrátit pomocí RETURN. Funkce ISBLANK vrací TRUE pokud je hodnota prázdná. V kombinaci s funkcí IF lze tedy výpočet podmínit na existenci hodnoty PreviousDailyCases, abychom zajistili smysluplnost dělení. Funkce BLANK vrací prázdnou hodnotu, pokud nelze zlomek vyjádřit.
Funkce CALCULATE je zde rozšířena o další vstup, kterým upravujeme (filtrujeme) výpočetní kontext. Nyní je tedy řečeno, že se má spočíst metrika x1 v kontextu, kde je datum posunuto o 7 dní do minulosti funkcí DATEADD.
Q4: Přidejte do vizuálu z Q3 sloupec s novou metrikou
x2. Jaký význam mají hodnotyx2v souhrnech?
Komentář
Hodnota asi na první pohled nedává smysl. Podívejte se nejprve na souhrny pro x1. Zde dochází k sečtení všech hodnot v příslušném měsíci. Zkuste upravit vzorec `x2` aby vracel pouze hodnotu `PreviousDailyCases`. Opět zde získáte celé číslo jako sumu hodnot v daném měsíci.V původním vzorci tedy má hodnota měsíčního souhrnu význam jako SUMA(1.MM.YYYY až 31.MM.YYYY) / SUMA (23.MM-1.YYYY až 24.MM.YYYY)
To mi nedává žádný relevantní význam.
Q5: Upravte vzorec
x2tak, aby využíval míruCount of id average per Datemístox1. Jak se změní význam hodnot?
Komentář
V souhrnech jsou nyní použity funkce AVERAGE ve smyslu AVERAGE(1.MM.YYYY až 31.MM.YYYY) / AVERAGE (23.MM-1.YYYY až 24.MM.YYYY)Klouzavé průměry (revisited)
V předchozí části jsme využili předpřipravenou míru pro klouzavý průměr. Ručně by šlo míry vytvořit průměr za 7 předcházejících dnů tímto způsobem:
![]()
x3 = CALCULATE( AVERAGEX( DATESINPERIOD('Kalendář'[Date], LASTDATE('Kalendář'[Date]), -7, DAY), [x1] ) )
Vzorec se podobá předchozímu, ale místo funkce DATESBETWEEN je použita funkce DATESINPERIOD, která vrací seznam dat v daném období. Konkrétně počítá od posledního dne aktuálního kontextu (tj. například aktuální den ve vizualizaci členěné po dnech, nebo poslední den měsíce ve vizualizaci členěné po měsících) a napočítá 7 dní zpět. Pro každou hodnotu je pak spočtena míra x1. Sada hodnot je pomocí funkce AVERAGEX zprůměrována a vrácena jako výsledek.
Q6: Vytvořenou míru přidejte opět do vizuálu jako další sloupec. Jaký význam mají souhrny tentokrát?
Odpověď
Stejná hodnota jako spočtená hodnota pro poslední den v měsíci.※ Stejně jako v původním klouzavém průměru nejsou prázdné hodnoty započteny jako nula.
Srovnání kategorie vůči celku
Momentálně nad vytvořenými měrami lze provádět filtraci. To lze vyzkoušet přidáním dalšího vizuálu, např. vizuál typu Matrix obsahující názvy krajů a denní počty nákaz, a aplikováním cross-filteru výběrem některého z krajů.
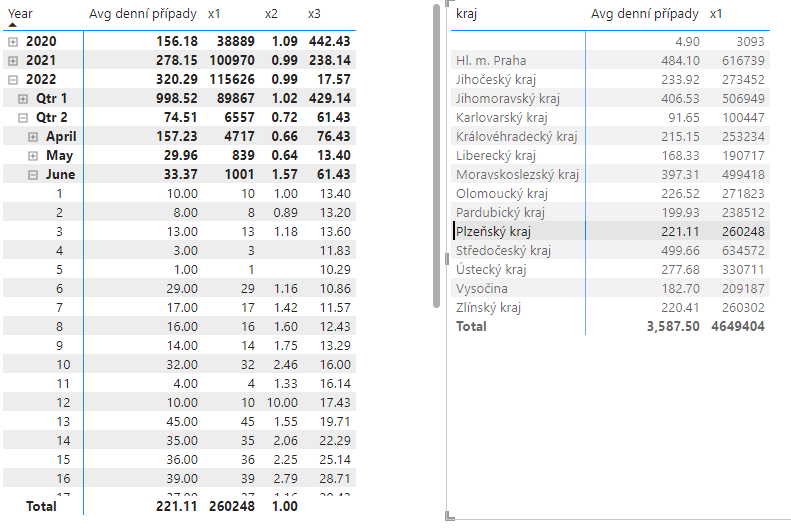 Fig — Přehledové tabulky s různými měrami. Levá tabulka je seskupena podle data, pravá tabula je seskupena podle krajů. Aplikována filtrace na Plzeňský kraj.
Fig — Přehledové tabulky s různými měrami. Levá tabulka je seskupena podle data, pravá tabula je seskupena podle krajů. Aplikována filtrace na Plzeňský kraj.
Abychom mohli spočíst poměry vůči celku, je potřeba vytvořit metriku, která bude vůči takovým filtracím odolná. Zavádím tedy míru x4 s následujícím vzorcem:
![]()
x4 = AVERAGEX( KEEPFILTERS('Kalendář'), CALCULATE(COUNTROWS('osoby'), FILTER(ALL('osoby'), 'osoby'[datum] = 'Kalendář'[Date]) ) )
Ve funkci AVERAGEX je nejprve použit pokyn KEEPFILTERS, který říká, že se má výpočet provést v kontextu aktuálních filtrů. Výpočetní blok je tedy prováděn nad tabulkou Kalendář, tedy budou spočteny hodnoty vztahující se ke kalendářním datům. Následně je použita funkce CALCULATE, která vrací počet řádků v tabulce osoby. Nad tabulkou je aplikován speciální FILTER, který nejprve ruší všechny kontextové filtry pomocí ALL a následně zavádí vlastní filtraci dle datumu. To je tedy jediný atribut, podle kterého je míra členěna.
Q7: Vytvořenou míru přidejte opět do vizuálu jako další sloupec. Aplikujte filtr podle kraje a pozorujte, jak se změní hodnoty v tabulce.
Pokud chceme míry pro jednotlivé kraje vůči celku, lze vytvořit novou metriku analogicky k x2 nebo x3 obsahující výpočet pro celek a následně v další metrice provést srovnávací operaci. Například:
![]()
x5 = VAR PreviousDailyCases = CALCULATE([x4], DATEADD('Kalendář'[Date], -7, DAY)) RETURN IF(ISBLANK(PreviousDailyCases) , BLANK(), ([x4] / PreviousDailyCases)
![]()
x6 = [x5] - [x4]
Kde x6 má význam rozdílu mezi mezitýdenním poměrem přírůstků ve filtrovaném segmentu vůči celku.
Výpočet dnů překonaných milníků počtu nákaz
Posledním příkladem bude využití míry pro určení, zda v daném dnu došlo k překročení některého milníku v kumulativním počtu případů.
![]()
x7 = VAR milestone = 100000 VAR CurrentDate = LASTDATE('Kalendář'[Date]) VAR CurrentCumulativeCount = CALCULATE(COUNTROWS('osoby'), 'Kalendář'[Date] <= CurrentDate) VAR PreviousCumulativeCount = CALCULATE(COUNTROWS('osoby'), 'Kalendář'[Date] < CurrentDate) VAR CurrentDivision = INT(DIVIDE(CurrentCumulativeCount, milestone)) VAR PreviousDivision = INT(DIVIDE(PreviousCumulativeCount, milestone)) RETURN IF( CurrentDivision <> PreviousDivision, CurrentDivision * milestone, 0 )
Ve vzorci je definovaná proměnná milestone určující, po kolika případech má být milník vyhlášen. Následně je do proměnné vložen aktuální datum (ve smyslu průchodu časovou řadou) a spočteno, kolik kumulativních případů bylo v daný den a kolik v předchozí den. Pokud jsou výsledky celočíselného dělení odlišené, došlo k překročení milníku a to je propsáno do výsledku. Míra vrací hodnotu překonaného milníku nebo nulu pro každý den.
Použít lze například opět jako vizuál Matrix s dny v prvním sloupci a hodnotou milníku ve druhém. Pokud se aplikuje filtrace na nenulové hodnoty milníků, budou zobrazeny pouze významné dny.
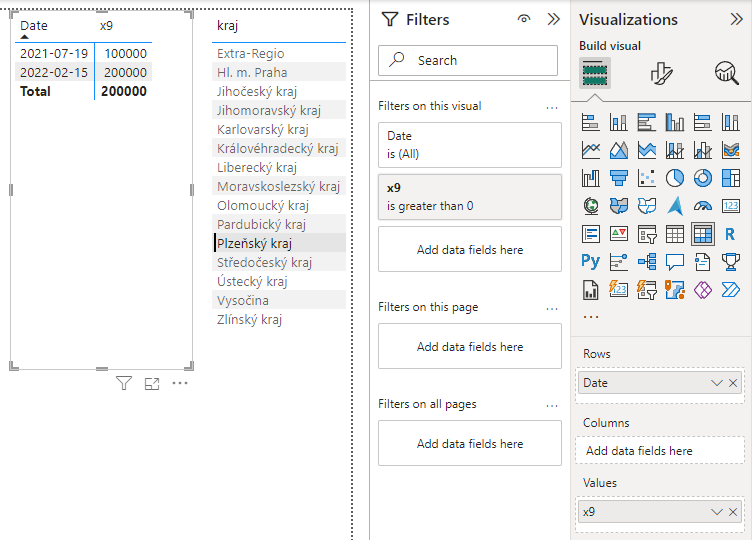 Fig — Vizualizace překročených statisícových milníků v Plzeňském kraji.
Fig — Vizualizace překročených statisícových milníků v Plzeňském kraji.