Gramatiky a nedeterministické konečné automaty
Vytvořte gramatiku, která bude nad abecedou {0, 1} generovat všechny řetězce obsahující lichý počet nul a sudý počet jedniček.
S trochou zkušeností odhadneme, že takový jazyk lze rozpoznávat konečným automatem. Jeho stavy si označíme zkratkami typu S0L1, konkrétně tato znamená "automat dosud načetl sudý počet nul a lichý počet jedniček".
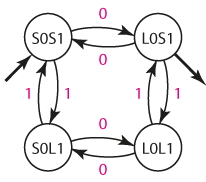
Pro potřeby tvorby gramatiky si stavy přejmenujeme na S, A, B, C:
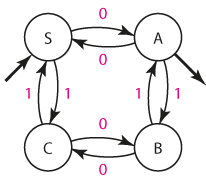
Nyní automat rutinně přepíšeme do podoby pravé lineární gramatiky:
S --> 0A | 1C
A --> 0S | 1B | e
B --> 0C | 1A
C --> 0B | 1S
Podotkněme, že uvedený způsobem nelze použít vždy, protože ne vždy jde sestavit konečný automat.
Vytvořte gramatiku generující identifikační čísla studentů ZČU nastupujících v letech 2010 až 2013. Příkladem platného studijního čísla je A13B0001K.
Na příkladu si ověříme, že vhodně zvolené názvy neterminálních symbolů poskytují přirozený nástroj, jak popsat strukturu řetězců.
Zaveďme si proto nové označení neterminálních a terminálních symbolů: slova ve špičatých závorkách budou označovat neterminální symboly, vše ostatní budou terminální symboly.
Gramatiku zapíšeme snadno:
<číslo> --> <fakulta> <rok> <typ studia> <číslo> <forma studia>
<fakulta> --> A | E | K | S | P | R | F | U
<rok> --> 10 | 11 | 12 | 13
<typ studia> --> B | N | P
<číslo> --> <cifra> <cifra> <cifra> <cifra>
<cifra> --> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
<forma studia> --> P | K
Převod pravé lineární gramatiky na konečný automat.
Je dána gramatika G. Vytvořte gramatiku G' v regulárním tvaru takovou, že L(G) = L(G')
S --> abA | bS | aa
A --> B | bbA
B --> aS | bbA | a
Při řešení je vhodné postupovat systematicky. Napřed opíšeme pravidla typu X --> qY a X --> e, která již regulární tvar mají:
S --> bS
B --> aS
Následně upravíme pravidla typu
X --> q1q2...qNY
na posloupnost pravidel
X --> q1X1
X1 --> q2X2
...
XN-1 --> qNY
Pravidla typu
X --> q1q2...qN
upravíme na posloupnost pravidel
X --> q1X1
X1 --> q2X2
...
XN-1 --> qNXN
XN --> e
Tedy:
S --> aS1 (z pravidla S --> abA)
S1 --> bA
S --> aS2 (z pravidla S --> aa)
S2 --> aS3
S3 --> e
A --> bA1 (z pravidla A --> bbA)
A1 --> bA
B --> bB1 (z pravidla B --> bbA)
B1 --> bA
B --> aB2 (z pravidla B --> a)
B2 --> e
Na závěr vyhledáme v původní gramatice pravidla typu X --> Y. Místo nich napíšeme pravidla X --> α, kde α je pravá strana všech dosud napsaných pravidel pro symbol Y. Ale pozor! Pokud se v původní gramatice současně vyskytuje pravidlo Y --> Z, musíme do nové gramatiky napsat i pravidla X --> β, kde β je pravá strana všech dosud napsaných pravidel pro symbol Z.
V naší gramatice bylo pouze pravidlo A --> B. Proto místo něj zapíšeme pravidla
A --> AS (z pravidla A --> B)
A --> bB1
A --> aB2
Výsledná gramatika G' v "kondenzované podobě" je tedy:
S --> bS | aS1 | aS2
S1 --> bA
S2 --> aS3
S3 --> e
A --> bA1 | AS | bB1 | aB2
A1 --> bA
B --> aS | bB1 | aB2
B1 --> bA
B2 --> e
Nikdy se nepokoušejte napsat gramatiku metodou "kouknu a vidím"! Velmi snadno na nějaké pravidlo zapomenete. Výše uvedený postup vám dává do psaní pravidel systém a riziko chyby je mnohem menší.
Převeďte gramatiku G' na nedeterminististický konečný automat A takový, že L(A) = L(G') = L(G)
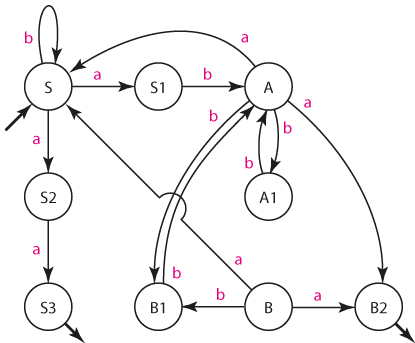
Vytvořte determinististický konečný automat A' takový, že L(A') = L(A) = L(G') = L(G)
Při konstrukci deterministického konečného automatu začneme tím, že si zapíšeme skupinu stavů, v nichž se může automat nacházet na začátku. Jsou to všechny počáteční stavy plus všechny stavy, které jsou s počátečními spojeny e-hranami. Náš automat žádné e-hrany nemá, proto je množina vstupních stavů rovna { S }.
Skupina stavů původního NKA představuje stav nového DKA. Konstrukce přechodové funkce je snadná: je-li NKA v některém ze stavů { A, B, C, ... } a na vstup přijde symbol q, sepíšeme všechny stavy, do nichž se může automat dostat. Tato skupina stavů je rovněž stavem DKA.
Například ze skupiny stavů { S } se mohl NKA dosta symbolem a do některého ze stavů { S1, S2 }, symbolem b jen do stavu S, formálně do skupiny stavů { S }.
Z počáteční skupiny stavů NKA tak typicky získáme několik nových skupin stavů. I ty musíme při konstrukci DKA vyšetřit. V našem případě musíme vyšetřit reakci automatu na skupinu stavů { S1, S2 }, protože skupinu stavů { S } jsme již vyšetřili.
Stejným způsobem postupujeme tak dlouho, až nám přestanou nové skupiny stavů vznikat. Pro náš NKA tak vznikne přechodová tabulka
| in/out | stav | a | b |
|---|---|---|---|
| in | { S } | { S1, S2 } | { S } |
| { S1, S2 } | { S3 } | { A } | |
| out | { S3 } | - | - |
| { A } | { S, B2 } | { A1, B1 } | |
| out | { S, B2 } | { S1, S2 } | { S } |
| { A1, B1 } | - | { A } |
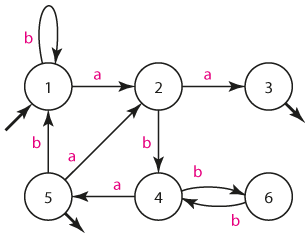
Všimněme si, že v tabulce jsme poznámkami in/out označili vstupní a výstupní stavy. Vstupní stav je pochopitelně jen jeden a je dán skupinou stavů, kde se NKA může nacházet na začátku. Výstupní stavy jsou všechny takové, které ve skupině obsahují alespoň jeden výstupní stav NKA, v našem případě S3 nebo B2.
Dále si všimněme, že jako reakce je někde zapsána pomlčka, např. ze skupiny stavů { S3 } automat není schopen nikam přejít. To je však pouze symbolické označení přechodu do chybového stavu.
Čistě pro přehlednost je vhodné na závěr stavy přeznačit, tj. např. stav { S } označíme číslem 1:
| in/out | stav | a | b |
|---|---|---|---|
| in | 1 | 2 | 1 |
| 2 | 3 | 4 | |
| out | 3 | - | - |
| 4 | 5 | 6 | |
| out | 5 | 2 | 1 |
| 6 | - | 4 |
Spojování automatů
Jsou dány gramatiky G1 a G2. Sestrojte nedeterministický konečný automat A takový, že
L(A) = L(G1)R ∪ L(G2), kde L(G1)R označuje reverzi jazyka.
G1: S --> aS | bbA G2: S --> Aba | Ab | B
A --> aaA | B A --> Aaa | B
B --> bbB | e B --> Bbb | e
Napřed sestrojíme konečný automat ke G1. Jediná záludnost, s kterou se musíme vypořádat, je pravidlo A --> B. Díky němu musí vést ze stavu A stejné přechody jako ze stavu B. Když tedy napřed vyřešíme stav B, snadno dokreslíme příslušné šipky i ke stavu A.
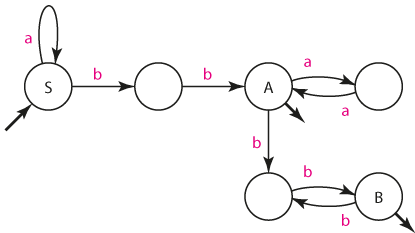
Automat A1
Když nyní "otočíme" všechny šipky (včetně indikátorů počátečních a koncových stavů), získáme automat A1' akceptující opačný jazyk, tedy L(A1') = L(A1)R.
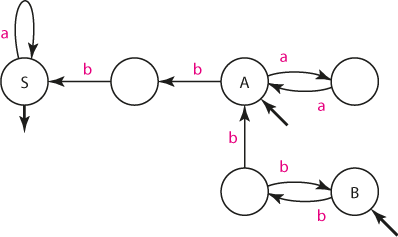
Automat A1'
Gramatika G2 je levorekurzivní, čili neumíme k ní přímo sestavit konečný automat. Můžeme ale snadno pravidla otočit a tím vytvořit gramatiku G2'. Pro ni platí, že L(G2') = L(G2)R.
G2': S --> abA | bA | B
A --> aaA | B
B --> bbB | e
K ní dokážeme snadno sestavit automat A2' takový, že L(A2') = L(G2').
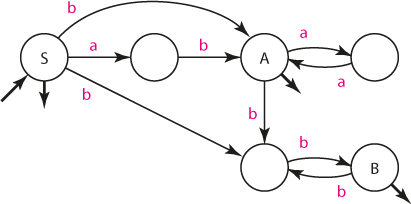
Automat A2'
(Všimněme si, že ze stavu B vedly dvě šipky - jedna prázdná, indikující koncový stav, a druhá představující přechod znakem b. Obě tyto šipky se musí objevit i ve stavech S, A, protože existují pravidla S --> B, A --> B.)
Když nyní "otočíme" všechny šipky (včetně indikátorů počátečních a koncových stavů), získáme automat A2 akceptující opačný jazyk, tedy L(A2) = L(A2')R.
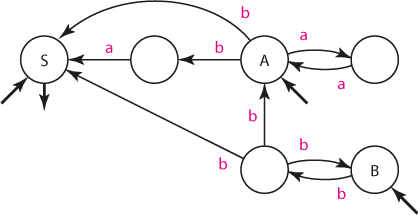
Automat A2
Dvojí reverzí (napřed jsme otočili gramatiku, pak konečný automat) jsme získali konečný automat akceptující stejný jazyk jako původní gramatika, tedy L(A2) = L(G2).
Chceme-li vytvořit automat A akceptující jazyk L(A) = L(G1)R ∪ L(G2), pouze vytvoříme pomocný vstupní stav propojíme jej e-hranou se výstupními stavy automatů A1' a A2. Dále vytvoříme pomocný výstupní stav a e-hranou jej propojíme s výstupními stavy automatů A1' a A2.
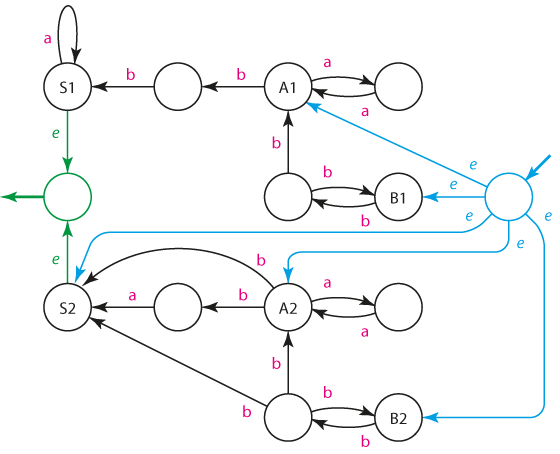
Výsledný automat
Samostatná práce: výsledný automat převeďte na deterministický.