Navrhněte NKA, který akceptuje všechny řetězce obsahující -abb- nebo -ba-
Řešení: NKA bujde mít zřejmě dvě větve (jednu sledující možnost -abb-, druhou pro možnost -ba-), přičemž o vstupu do jedné či druhé větve se automat "rozhodne" nedeterministicky. Obě větve pak sloučíme do akceptačního stavu.
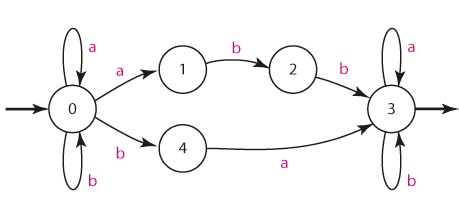
| in/out | stav | a | b |
|---|---|---|---|
| in | 0 | 0, 1 | 0, 4 |
| 1 | - | 2 | |
| 2 | - | 3 | |
| out | 3 | 3 | 3 |
| 4 | 3 | - |
NKA z předchozího příkladu převěďte na DKA
Řešení: Díky neexistenci e-hran je situace jednodušší. Na začátku činnosti musí být NKA ve stavu 0; v případě NKA říkáme, že se automat nachází v libovolném z množiny stavů {0}; hovoříme též o konfiguraci.
Je-li NKA v konfiguraci {0} a na vstup přijde "a", může automat buď zůstat ve stavu 0, nebo přejít do stavu 1; říkáme, že NKA přechází do konfigurace {0,1}. Obdobně usoudíme, že vstupem "b" přejde NKA z konfigurace {0} do konfigurace {0,4}. Tak sestavíme přechodovou tabulku mezi konfiguracemi.
| in/out | stav | a | b |
|---|---|---|---|
| in | {0} | {0,1} | {0,4} |
| {0,1} | {0,1} | {0,2,4} | |
| {0,4} | {0,1,3} | {0,4} | |
| {0,2,4} | {0,1,3} | {0,3,4} | |
| out | {0,1,3} | {0,1,3} | {0,2,3,4} |
| out | {0,3,4} | {0,1,3} | {0,3,4} |
| out | {0,2,3,4} | {0,1,3} | {0,3,4} |
Tabulka se dá samozřejmě chápat jako popis přechodové funkce DKA. Pro přehlednost můžeme konfigurace pojmenovat písmeny A-G:
| in/out | stav | a | b |
|---|---|---|---|
| in | A | B | C |
| B | B | D | |
| C | E | C | |
| D | E | F | |
| out | E | E | G |
| out | F | E | F |
| out | G | E | F |
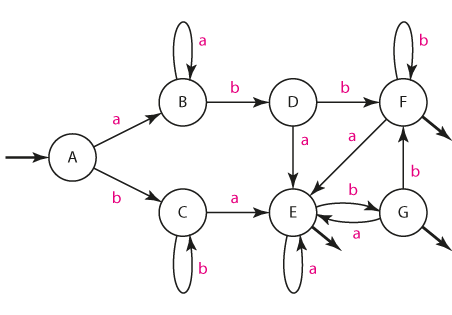
Automat z předchozího příkladu minimalizujte
Řešení: Myšlenka minimalizace je založena na sloučení stavů do skupin; z vnějšího pohledu se všechny stavy jedné skupiny musí chovat rovnocenně. Algoritmus nejprve rozdělí veškeré stavy do dvou skupin (výstupní a ne-výstupní), prozkoumá rovnocennost stavů v nich obsažených a v případě potřeby skupiny rekurzivně rozděluje.
V prvním kroku tedy rozdělíme stavy do skupin I = {A, B, C, D} a II = {E, F, G}, tj. sloučíme všechny ne-výstupní stavy do skupiny I a všechny výstupní do skupiny II. Přechodovou tabulku formálně přepíšeme:
| původní značení | nové značení | |||||
|---|---|---|---|---|---|---|
| in/out | stav | a | b | skupina | a | b |
| in | A | B | C | I | I | I |
| B | B | D | I | I | I | |
| C | E | C | I | II | I | |
| D | E | F | I | II | II | |
| out | E | E | G | II | II | II |
| out | F | E | F | II | II | II |
| out | G | E | F | II | II | II |
Vidíme, že stavy skupiny II se chovají konzistentně: všechny jsou výstupní a po přijetí znaku "a" automat vždy přejde do stavu skupiny II, obdobně po přijetí znaku "b".
Naproti tomu skupina I konzistentní není: někdy (v první řádce) přejde automat po znaku "a" do stavu skupiny I, jindy (v třetí řádce) do stavu skupiny II. Skupinu I = {A, B, C, D} proto rozdělíme na skupiny III = {A, B} a IV = {C, D} a tabulku přepíšeme:
| původní značení | nové značení | |||||
|---|---|---|---|---|---|---|
| in/out | stav | a | b | skupina | a | b |
| in | A | B | C | III | III | IV |
| B | B | D | III | III | IV | |
| C | E | C | IV | II | IV | |
| D | E | F | IV | II | II | |
| out | E | E | G | II | II | II |
| out | F | E | F | II | II | II |
| out | G | E | F | II | II | II |
Skupina III je konzistentní, skupina IV celkem pochopitelně ne. Rozdělíme ji proto na skupiny V = {C} a VI = {D}:
| původní značení | nové značení | |||||
|---|---|---|---|---|---|---|
| in/out | stav | a | b | skupina | a | b |
| in | A | B | C | III | III | V |
| B | B | D | III | III | VI | |
| C | E | C | V | II | V | |
| D | E | F | VI | II | II | |
| out | E | E | G | II | II | II |
| out | F | E | F | II | II | II |
| out | G | E | F | II | II | II |
Všimněme si, že posledním rozdělením se stala skupina III nekonzistentní - vstupem "b" přejde v první řádce automat do skupiny V, v druhé řádce do skupiny VI. Proto musíme přistoupit k rozdělení skupiny III na skupiny VII = {A} a VIII = {B}:
| původní značení | nové značení | |||||
|---|---|---|---|---|---|---|
| in/out | stav | a | b | skupina | a | b |
| in | A | B | C | VII | VIII | V |
| B | B | D | VIII | VIII | VI | |
| C | E | C | V | II | V | |
| D | E | F | VI | II | II | |
| out | E | E | G | II | II | II |
| out | F | E | F | II | II | II |
| out | G | E | F | II | II | II |
Nyní jsou skupiny stavů bezkonfliktní. Skupiny můžeme pro přehlednost přejmenovat; v každém případě už jsme u konce.
| in/out | stav | a | b |
|---|---|---|---|
| in | A' | B' | C' |
| B' | B' | D' | |
| C' | E' | C' | |
| D' | E' | E' | |
| out | E' | E' | E' |
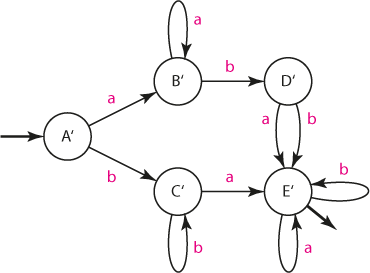
Navrhněte NKA, který akceptuje řetězce popsané regulárním výrazem
a(a+b)* + (a+b)*aa(a+b)*. Určete e-následníky.
Řešení: Postupným rozkladem regulárního výrazu dojdeme k NKA:
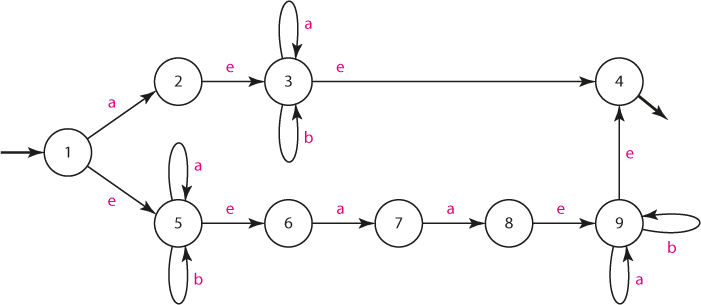
Na automatu si procvičíme hledání e-následníků, tj. stavů, do nichž se může automat ze stavu X samovolně dostat.
| stav | e-následníci |
|---|---|
| 1 | {1, 5, 6} |
| 2 | {2, 3, 4} |
| 3 | {3, 4} |
| 4 | {4} |
| 5 | {5, 6} |
| 6 | {6} |
| 7 | {7} |
| 8 | {8, 9, 4} |
| 9 | {9, 4} |
NKA z předchozího příkladu zjednodušte slučováním stavů a převeďte na DKA
Řešení: Za prvé si můžeme všimnout, že někdy je posloupnost "stav - e-hrana - stav" zbytečná a lze ji sloučit do jediného stavu. V automatu najdeme hned tři takové případy:
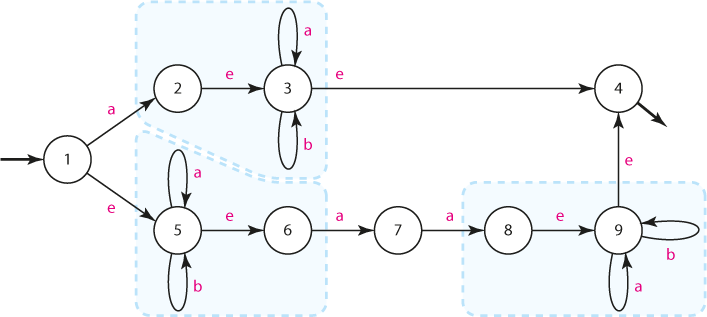
Vyznačené skupiny můžeme sloučit do nových stavů:
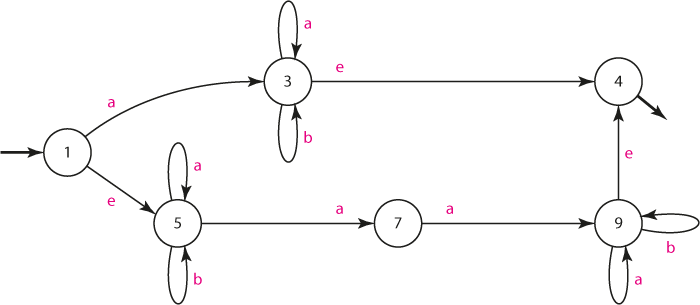
Nyní si můžeme všimnout, že stavy 3 a 9 se chovají ekvivalentně: automat v nich vydrží jak vstupem "a", tak vstupem "b", a v obou případech může e-hranou přejít do stavu 4. Mohli bychom proto stavy 3 a 9 sloučit do stavu jediného.
Pokud úvahu rozvedeme, uvědomíme si, že díky e-hranám 3→4 a 9→4 můžeme do jediného stavu sloučit stavy 3, 9 a 4:
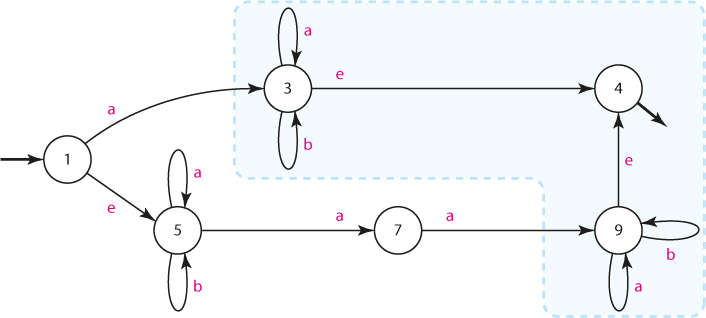
V nově vyznačené skupině totiž automat setrvává jak vstupem "a", tak vstupem "b", a díky e-hranám je vlastně jedno, zda je koncový pouze stav 4, nebo i stavy 3 a 9. Po úpravě proto:
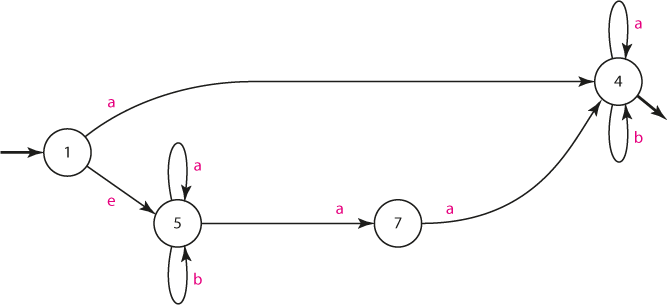
Před převodem na DKA si sepišme e-následníky:
| stav | e-následníci |
|---|---|
| 1 | {1, 5} |
| 4 | {4} |
| 5 | {5} |
| 7 | {7} |
Nyní můžeme snadno převést NKA na DKA:
| in/out | stav | a | b |
|---|---|---|---|
| in | {1,5} | {4, 5, 7} | {5} |
| out | {4, 5, 7} | {4, 5, 7} | {4, 5} |
| {5} | {5, 7} | {5} | |
| out | {4, 5} | {4, 5, 7} | {4, 5} |
| {5, 7} | {4, 5, 7} | {5} |
Po přeznačení stavů:
| in/out | stav | a | b |
|---|---|---|---|
| in | A | B | C |
| out | B | B | D |
| C | E | C | |
| out | D | B | D |
| E | B | C |
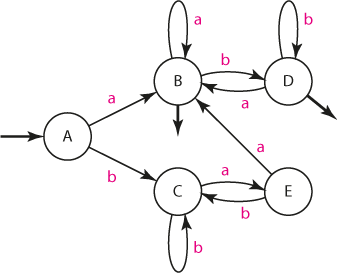
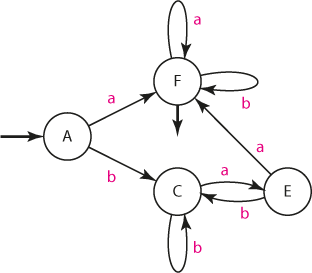
Při minimalizaci bychom opět začali slučováním výstupních a ne-výstupních stavů do skupin. Snadno se přesvědčíme, že oba výstupní stavy B, D můžeme sloučit do jediného stavu, nazvěme si ho F:
Automat z předchozího příkladu převeďte na regulární výraz a srovnejte jej s výchozím RV
a(a+b)* + (a+b)*aa(a+b)*
Řešení: Postupným zjednodušováním automatu dostaneme
a(a+b)* + bb*a(bb*a)*a(a+b)*
Výraz sice můžeme vytknutím (a+b)* zjednodušit na
[a + bb*a(bb*a)*a] (a+b)*
ale ani úprava nám o struktuře výrazu mnoho neřekne - uvnitř hranatých závorek čteme, že řetězec má začínat na buď na "a", nebo na jakýsi komplikovaný výraz, a za hranatými závorkami čteme, že na zbytku výrazu nezáleží. Naproti tomu původní regulární výraz
a(a+b)* + (a+b)*aa(a+b)*
můžeme přečíst celkem snadno: má jít o řetězec začínající znakem "a" nebo o řetězec obsahující sekvenci "aa".
Ačkoliv můžeme po jistém úsilí tutéž informaci vyčíst i z regulárního výrazu odvozeného z posledního DKA, je poučení z příkladu zřejmé: zatímco je poměrně snadné zkonsruovat regulární výraz, jeho "přirozená" interpretace nemusí být snadná; rovněž není snadné zjistit, zda dva regulární výrazy popisují stejné jazyky.